V listopadu jsem byl kromě OpenAltu ještě na SuriConu v Praze. Suricata má už deset let a je to velký open source projekt. Na konferenci jsem si udělal pár poznámek..
Co je nového v suricatě
Projekt se točí kolem několika málo lidí. Jeho hlavní vývojář je Viktor Julien, který mluvil o tom co se udělalo za poslední rok a o tom co se v tom příštím roce chystá. Ve čtverce byla přidána podpora programovacího jazyka Rust, jehož nejdůležitější vlastností je hlídání paměťových rozsahů. Viktor plánuje pracovat na parseru pro SMB2 a 3. Chce ho napsat právě v Rustu. Jeho cílem je umožnit extrahování souborů z SMB provozu a vytvoření klíčových slov pro sambu tak, aby se dala psát pravidla.

O tom jak se v Rustu píší parsery měl potom přednášku Piere, který napsal NTP parser pro Suricatu 4. Jeho parser umí v podstatě jenom potvrdit, jestli se jedná o validní NTP, což není úplně málo, ale ani úplně moc.
V pravidlech se objevili nové klíčové slova compress_whitespaces a strip_whitespaces, které by měli zjednodušit psaní pravidel a zabránit připadům, kdy se hledá shoda v md5 obsahu, ale kvůli pár mezerám je potřeba mít více pravidel. Pokud máme obsah v base64, tak musíme kvůli mezerám dělat 3 pravidla. V rámci pravidla jde také obsah dekodovat z base64 a dělat detekci přímo na obsahu.
Dalším novým klíčovým slovem pro prahování je by_both, které použije celý pár (obě IP adresy).
Mezi Suricatou 3 a 4 je vůbec spoustu rozdílů ve psaní pravidel. Čtverka toho umí víc a rychleji. Pěknou přednášku k tomu měli kluci z Proofpointu, kde se snažili na příkladech ukázat jak upravit staré pravidla. Ostatně oznámili přechod na nové lepší pravidla..
Pokud chceme dělat identifikaci aplikace. Aplikace jsou například Jira, WordPress, Drupal, Redmine nebo bugzilla. Když k tomu chceme vytvořit nějaké pravidlo, tak použijeme klíčové slovo flowbits. Viktor slíbil, že by měli v upstreamu vzniknout vzorová pravidla pro identifikace nejznámějších aplikací.
Algoritmus Hyperscan řeší dobře problém hledání podřetězce v řetězci (Multi pattern match MPM), ale je omptimalizovaný pouze pro Intel. Suricata oproti tomu umí ještě algoritmus Aho Korashic, ten byl doplněný o mechanismus depth a offset podobně jako je v hyperscanu, takže by se měl zase malinko zrychlit.
Jedním ze způsobů, kterým se dá ovládat suricata je unix socket. Příkazy se do něj dávají pomocí jsonu. Nově by mělo vzniknout rozhraní pro přehrávání všech PCAPů v adresáři pomocí příkazu přes tento socket. Erik mluvil v téhle spojitosti o “pikap diži”. Docela dlouho mi trvalo, než jsem ve Francouzkém přízvuku rozpoznal PCAP DJ. (-;
Suricata 4 loguje kromě samotného eventu i další metadata, takže při následném zpracovaní kibanou/logstashem/elastickem se snáze dostaneme k dalším informacím.
Erik měl říct něco i o XDP/eBPF, ale tuhle přednášku jsem nestihl. V postatě se ale jedná o mechanizmus, který umožní zaříznout zpracování dat už na úrovni kernelu, takže to výrazně ušetří výkon.
Kouzelné zvířátko
Randy mluvil o tom jak spojil suricatu přes Lua s Redisem a Redis ML. Udělali klasifikátor nad DNS protoklem. Vyextrahovali 21 příznaků jako délka TLD, délka celého doménového jména, jestli obsahuje .gov, jaké je procento číslic v doméně apod. Logistickou regresí natrénovali model (offline) a pak dělali klasifikaci (online). Přes unix socket nastavili hostbits a ten vyvolal event.
suricatasc -‐c “add-‐hostbit <ip> <bit name> <expire in seconds>”
suricatasc -‐c “add-‐hostbit 1.2.3.4 blacklist 3600″alert ip any any -‐> any any (msg:”blacklist by mobster”; hostbits:isset,blacklist; sid:1000;)
Pro trénování použili dns jména, které měli domény hlášené suricatou (kategorie Malware CnC server, Known Infected Bot, Spyware CnC, P2P CnC, a totéž pro mobilní malware).
K tomu přidali doménové jména tzv. Bening sites (Alexa Domains) a nějaký seznam skutečných firem a jejich domén.
Dosáli 81% úspěšnosti (True Positive Rate) klasifickace při práhu 0.05 a 5% chybovosti (False Positive Rate).
Machine learning a klasifikace je vůbec trend poslední doby. Anthony ze Splunku mimojiné popisoval jak pomocí klasifikace a příznaků z toků klasifikoval SSH klienta.
Flowsynth a Dalton
Moje open source srdíčko potěšilo, že kluci ze secureworks otevřeli dva velmi zajímavé nástroje flowsynth a dalton.
Flowsynth je nástroj pro generování pcapů podle zadaných pravidel. Prostě zadáte jak má vypadat http request a co má obsahovat a ono to vygeneruje celý pcap. Řeší to takové ty nezajímavé věci, jako je rozdělení tcp spojení do několika packetu (CONTINUATION), TCP handshake (SYN, ACK, FIN, ..).
# the commands below describe a simple HTTP request
my_connection > (content:”GET / HTTP/1.1\x0d\x0aHost:google.com\x0d\x0a\x0d\x0a”;);
my_connection < (content:”HTTP/1.1 200 OK\x0d\x0aContent-Type: text/html\x0d\x0a\x0d\x0a”; content:”This is my response body.”;);
Ve chvíli kdy potřebujeme napsat a otestovat nějaké pravidlo do suricaty, tak to může ušetřit docela dost času.
Nástroj Dalton je potom takové jednoduché gui, které má usnadnit psaní a testování pravidel do suricaty. Do textového pole napíšeme pravidlo, vybereme verzi suricaty nebo snortu, vybereme pcap a dáme play. Za pár vteřin už se koukáme na výstupy z logu suricaty. Místo pcapu samozřejmě můžeme napsat pcap ve flowsynthu. Dalton je napsaný v Djangu, Jinja a Flasku. Dalton-Agent je potom instance suricata nebo snort používaná k detekci. Všechno je to samozřejmě zabalené v dockeru, takže se to dá všude snadno nasadit.
Suricata v Cloudu
Michal Purzynski na přednášce říkal příběh o migrování Mozilly do Cloudu. Rozhodnutí přesunout všechno do cloudu tam padlo před pár lety (5?) a ještě se jim to nepodařilo zmigrovat do cloudu a už některé věci migrují už zpět do datacenter.
Řešil problém jak dobře nasadit suricatu v cloudu. Variant bylo několik. Například nasadit suricatu přímo s aplikací. To přináší spoustu komplikací (například závislosti). Další možností jak data dostat z AWS je udělat GRE tunel a posílat data tímto tunelem. Suricata je jen IDS a její výstupy se posílají dál přes syslog do SNS, pak do SQS a ty potom zpracovává nějaký SIEM. Dozvěděl jsem se spoustu dalších nových hipsterských výrazů jako je LB, VPC, credstash, aws kms, kinesis aws, kafka..
Suricata Roadmap a co bude příští rok
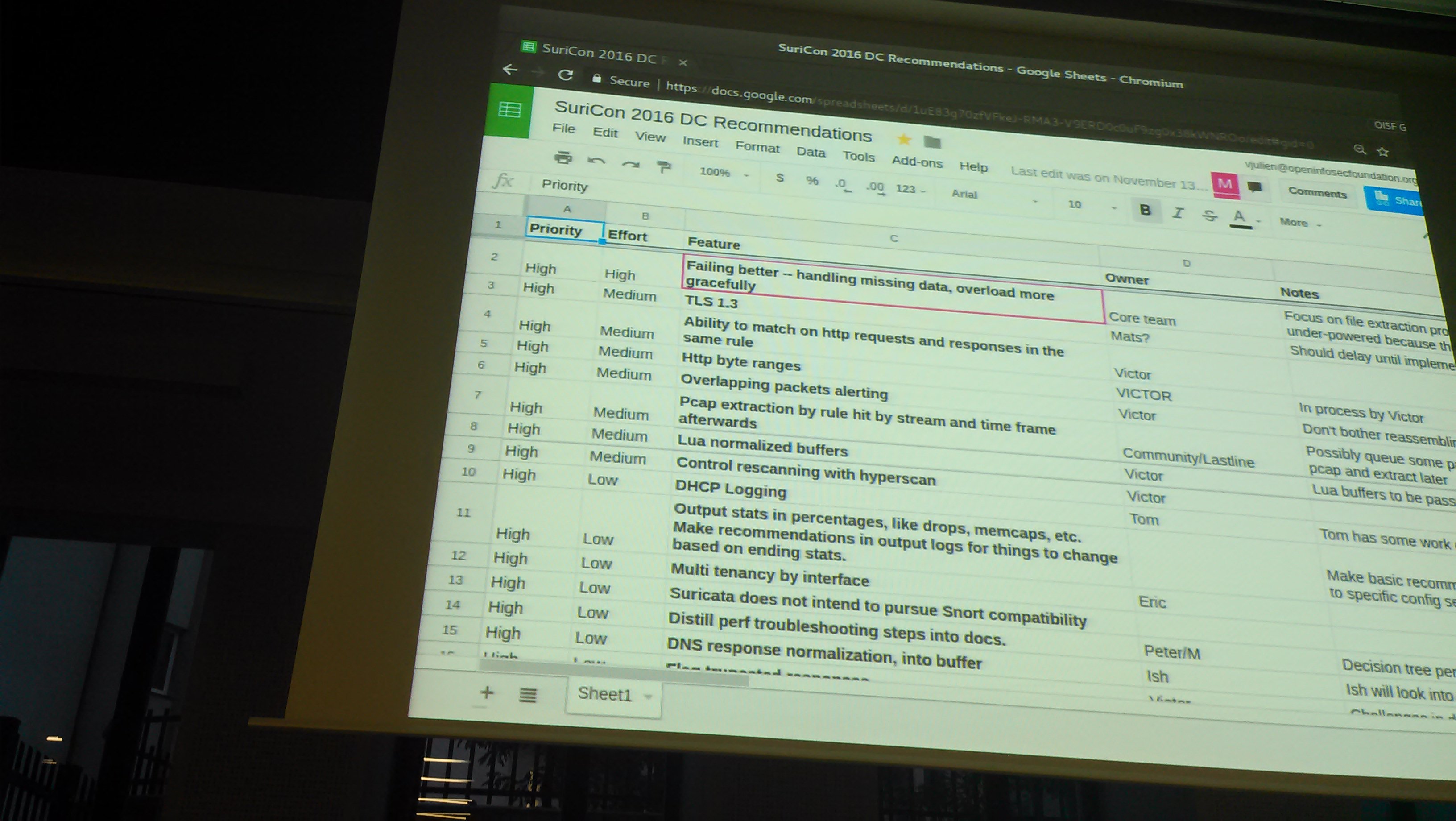
Závěr konference byl v duchu diskuse o tom co by mělo být v příštích verzích suricaty. Diskusi vedl v podstatě Viktor s Erikem, Janoshem a Petrem. Procházeli google drive spreadsheet a vyjadřovali se k jednotlivým vylepšením navrhovanými už vloni.

Jenom pár poznámek z toho co pro mně bylo nového a utkvělo mi
Z SSK finerprintu se dá říct o jaký prohlížeč se přesně jedná. Existuje JA3 databáze SSL fingerprintů.
Jeden z účastníků konference řešil problém parsování provozu jednom jedné strany komunikace. Z dávných dob si pamatuju řešení, kdy se dial-up používál jenom pro upload a pro download se používalo satelitní spojení. Jeden směr komunikace tedy šel úplně jiným kanálem jako ten druhý směr. Netušil jsem, že toto ještě někdo používá.
Zajímavé by bylo kdyby suricata uměla dávat informaci o poměru odesílaných a příjmaných dat (Producer Consumer Ratio). Problém obvykle nastává když se z consumera stane producer.
Dalším z problémů, který se řeší jsou dlouhotrvající toky. Podle RFC může být TCP spojení otevřené bez nějaké komunikace poměrně dlouho. Padl návrh, že by se mělo zavést klíčové slovo connection_age, které bude možné dát do pravidla a dlouho trvající spojení umožní aspoň detekovat.
Zdá se, že možnost ukládat přenesené soubory používá hodně lidí. S milionem souborů v jednom adresáři se nepracuje úplně dobře. V budoucnu by se soubory měli ukládat do adresářové struktury, kde jméno adresáře by mohlo být tvořeno z md5 hashe. Současně by měl vzniknout nějaký “helper skript” pro údržbu a promazávání těchto adresárů. Tenhle skript by mohl dělat i další činnosti, jako například hlídání global memcap a přenastavení suricaty v případě jeho překročení.
Hallway track a poznámky mezi řádky
Chodbový track konferencí bývá jeden z nejzajímavějších a človek se tam toho dozví strašně moc. V tomhle případě si ale spíš nepamatuju souvislosti (-;
Ptal jsem se Erika jak se napíše v pravidlu regulární výraz, který by nalezený výraz vložil do výstupu do logu. Prý existuje proof of concept implementace. Erik říkal, že na tom bude pracovat. Prý to není úplně složité a jen je potřeba doladit syntaxi.
Viděl jsem tam pár zajímavých nástrojů. Například graylog na vizualizaci a hledání v IDS událostech. Nebo yara pro další analýzu dat. Viktor chtěl původně yara nějak integrovat se suricatou, ale nějak z toho sešlo. Viktor měl na notebooku samolepku laikaboss, takže to je asi nový projekt, který preferuje (-;
Malware, malware, malware, oy!
Ono vlastně celá konference byla o tom jak najít malware (kromě velkého bratra) a další nehezké chování na síti.
Několik random citátů na závěr:
E-mail je dnes stále nejrozšířenější metoda pro distribuci malware.
A pak následovalo několik slajdů o tom jak se malware šíří přes sociální sítě a jiné messaging služby.
Makra ve wordu jsou stále velice rozšířená pro malware.
Libreoffice usilovně pracuje na tom, aby podporoval i malware napsaný pro Microsoft Office.
Porno stránky, kasína a free úložiště jsou dalším častým zdrojem malware.
Na porno v práci koukáte abyste našli nějaký malware..
Jo a když se budete snažit odvést pozornost od prezentace, tak na každý slajd přidejte nějakou animovanou blbost a mluvte čenglish nebo s jiným silným přízvukem (-;
![]()